Science
Google and UC Riverside Launch Advanced Tool to Combat Deepfakes
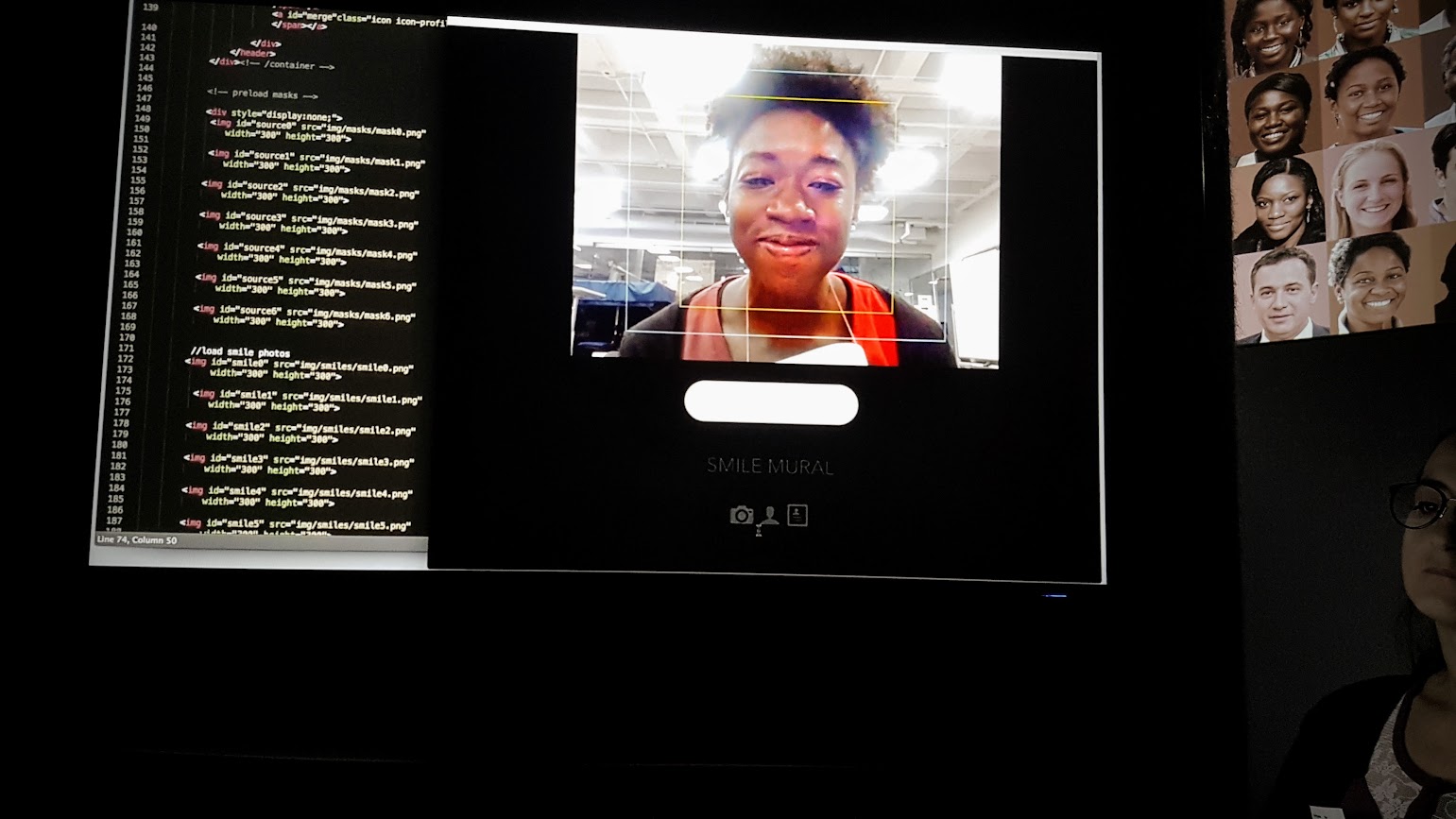
Deepfake technology is evolving rapidly, making it increasingly challenging to distinguish between real and fabricated videos. To combat this growing issue, researchers from the University of California, Riverside have partnered with Google to develop a groundbreaking system called the Universal Network for Identifying Tampered and synthEtic videos, or UNITE. This innovative tool is designed to detect deepfakes even when facial features are not visible.
As the landscape of misinformation shifts, UNITE sets itself apart from traditional detection methods. It employs advanced techniques to analyze not just faces, but entire video frames, including backgrounds and motion patterns. This approach enables the identification of synthetic videos that are often missed by existing detection systems, which typically rely heavily on facial recognition.
The rise of deepfakes, a term combining “deep learning” and “fake,” raises significant concerns. While these AI-generated videos can be amusing or entertaining, they are increasingly being used to impersonate individuals and mislead audiences. Current detection technology often struggles with non-facial content, allowing misinformation to proliferate in various formats. For instance, altering a scene’s background can distort reality just as effectively as manipulating a person’s image.
How UNITE Operates
UNITE employs a transformer-based deep learning model to scrutinize video clips for subtle inconsistencies that previous systems might overlook. The model utilizes a foundational AI framework known as Sigmoid Loss for Language Image Pre-Training (SigLIP), which allows it to extract features that are not tied to specific individuals or objects. A novel training technique, termed “attention-diversity loss,” encourages the model to focus on multiple visual regions within each frame, thus avoiding an overemphasis on facial data.
The collaboration with Google has granted the researchers access to extensive datasets and computational resources, enabling them to train the model on a diverse array of synthetic content. This includes videos generated from text or still images—formats that frequently challenge existing detection methods. The result is a universal detector capable of identifying various forgeries, from simple facial swaps to entirely synthetic videos created without any original footage.
Significance of the Development
The introduction of UNITE comes at a critical time when text-to-video and image-to-video generation tools have become widely accessible online. These AI-driven platforms allow nearly anyone to produce convincing videos, posing serious risks to individuals and institutions, and potentially undermining democratic processes in certain contexts.
The researchers unveiled their findings at the 2025 Conference on Computer Vision and Pattern Recognition (CVPR) held in Nashville, U.S.. Their paper, titled “Towards a Universal Synthetic Video Detector: From Face or Background Manipulations to Fully AI-Generated Content,” details the architecture and training methodologies employed in UNITE.
The ongoing evolution of deepfake technology underscores the urgent need for robust detection tools like UNITE. As misinformation continues to proliferate, such advancements will be crucial for newsrooms, social media platforms, and other organizations striving to safeguard the truth and maintain public trust.

Carney Budget Lacks Human and Environmental Focus in 2024

Psychologists Criticize Decision to Lower Education Standards
Czech Republic Commits US$19 Billion to Nuclear Expansion Project

Heather Smith Wins Governor General’s Literary Award for “Tig”
Google and UC Riverside Launch Advanced Tool to Combat Deepfakes

Durham Police Report Raises Alarm Over Mental Health Practices

Montgomery Man Sentenced to 25 Years for 2022 Murder

St. Clair College Students Call for Changes to Bus Pass System

Bond Market Gains from Fed Rate Cut Expectations Amid Weak Labor

Sauk Valley Chamber of Commerce Launches Nominations for Award

Brandon University’s Failed $5 Million Project Sparks Oversight Review

Winnipeg Celebrates Culinary Creativity During Le Burger Week 2025

Microsoft Confirms U.S. Law Overrules Canadian Data Sovereignty

Montreal’s Groupe Marcelle Leads Canadian Cosmetic Industry Growth
Tech Innovator Amandipp Singh Transforms Hiring for Disabled

Dragon Ball: Sparking! Zero Launching on Switch and Switch 2 This November

Red River College Launches New Programs to Address Industry Needs
Google Pixel 10 Pro Fold Specs Unveiled Ahead of Launch

Discord Faces Serious Security Breach Affecting Millions

Rocket Lab Reports Strong Q2 2025 Revenue Growth and Future Plans
-
 Education2 months ago
Education2 months agoBrandon University’s Failed $5 Million Project Sparks Oversight Review
-
 Lifestyle3 months ago
Lifestyle3 months agoWinnipeg Celebrates Culinary Creativity During Le Burger Week 2025
-
 Science3 months ago
Science3 months agoMicrosoft Confirms U.S. Law Overrules Canadian Data Sovereignty
-
 Health3 months ago
Health3 months agoMontreal’s Groupe Marcelle Leads Canadian Cosmetic Industry Growth
-

 Science3 months ago
Science3 months agoTech Innovator Amandipp Singh Transforms Hiring for Disabled
-
 Technology3 months ago
Technology3 months agoDragon Ball: Sparking! Zero Launching on Switch and Switch 2 This November
-
 Education3 months ago
Education3 months agoRed River College Launches New Programs to Address Industry Needs
-

 Technology3 months ago
Technology3 months agoGoogle Pixel 10 Pro Fold Specs Unveiled Ahead of Launch
-
 Technology1 month ago
Technology1 month agoDiscord Faces Serious Security Breach Affecting Millions
-
 Business2 months ago
Business2 months agoRocket Lab Reports Strong Q2 2025 Revenue Growth and Future Plans
-

 Science3 months ago
Science3 months agoChina’s Wukong Spacesuit Sets New Standard for AI in Space
-

 Education3 months ago
Education3 months agoAlberta Teachers’ Strike: Potential Impacts on Students and Families
-

 Technology3 months ago
Technology3 months agoWorld of Warcraft Players Buzz Over 19-Quest Bee Challenge
-

 Business3 months ago
Business3 months agoNew Estimates Reveal ChatGPT-5 Energy Use Could Soar
-

 Business3 months ago
Business3 months agoDawson City Residents Rally Around Buy Canadian Movement
-
 Technology1 month ago
Technology1 month agoHuawei MatePad 12X Redefines Tablet Experience for Professionals
-

 Education3 months ago
Education3 months agoNew SĆIȺNEW̱ SṮEȽIṮḴEȽ Elementary Opens in Langford for 2025/2026 Year
-

 Technology3 months ago
Technology3 months agoFuture Entertainment Launches DDoD with Gameplay Trailer Showcase
-

 Business3 months ago
Business3 months agoBNA Brewing to Open New Bowling Alley in Downtown Penticton
-

 Technology3 months ago
Technology3 months agoInnovative 140W GaN Travel Adapter Combines Power and Convenience
-

 Science3 months ago
Science3 months agoXi Labs Innovates with New AI Operating System Set for 2025 Launch
-

 Technology3 months ago
Technology3 months agoGlobal Launch of Ragnarok M: Classic Set for September 3, 2025
-

 Technology3 months ago
Technology3 months agoNew IDR01 Smart Ring Offers Advanced Sports Tracking for $169
-

 Technology3 months ago
Technology3 months agoDiscover the Relaxing Charm of Tiny Bookshop: A Cozy Gaming Escape